Java基础笔记
Java语言基础笔记
interface 接口
1 | |
interface接口可以理解为一种特殊的抽象类,对抽象类进一步特殊化,是抽象方法的集合。
接口不可以被*实例化**,但可以被实现***。但是Java 8之后改进为允许定义默认方法和实现
更过详见gitee的wiki——《抽象类与接口》
container 容器
container内容比较复杂,简单来说,是Java为开发者提前造好的轮子,就字面意思理解为==存放数据的容器==,解决基本数据类型(如数组)不能解决的问题。
此外还会涉及到数据结构、线程安全等的问题。
常用的部分container
Collection **==元素==**的集合
一、List 元素可重复
List.toArray()把List转化为Array(Object数组)
1. Vector:已经被弃用(From JDK1.5),线程同步
Stack:是满足后进先出的容器,但LinkedList可以实现所有栈功能
- ArrayList:可以动态增长的数组,默认长度是10。
随机访问快,插入删除慢。- LinkedList:同时属于Collection和Queue) :用链表实现的容器。可以实现很多队列、栈的数据结构。
查找慢(遍历整个链表),插入删除快。
二、Queue 队列 先进后出FILO
LinkedList (同时属于Collection和Queue)
PriorityQueue 优先级队列
三、Set 集合 元素不可重复
- HashSet:底层使用散列函数,查询方面有优化
LinkHashSet
- TreeSet:底层使用红黑树
Map **==键值对==**的集合
- HashMap 适合查找、删除、插入
- TreeMap 适合遍历
上述表述极不全面,待补充。
多态Polymorphism
多态指的是一个引用变量在程序中可以充当多种角色。细化地讲,比如可以将一个类的引用变量赋值为其子类的实例,如代码:
1 | |
在多态问题中,还存在函数调用的问题:
- 如上例语句3中,an3只能调用Animal的方法,因为不能保证Animal中有子类的方法。只有声明部分明确声明为子类类型时,其引用变量才能调用对应子类的方法
- 动态调用问题:若子类和父类同时含有相同名称的方法,默认调用最能体现具体特点的子类方法。
instanceof运算符能判断具体的实例是否满足某个特定的类型。
异常Exception
异常的介绍
Java中所有能被抛出的对象都视为Throwable类的实例,Exception和Error都是Throwable类的子类。
其中:
- Error表示程序遇到的严重错误,几乎无法挽回。
- Exception程度轻一点,比如打开一个不存在的文件。
进一步地,Java将运行时异常(RuntimeException)定性为非检查性异常(unchecked exceptions),而所有其它异常定性为检查性异常(checked exceptions)。
前者在运行时出现,由于运行程序的各种不可预见性,所以称之为“unchecked”。
后者在程序开发中可预见,因此称之为“checked”(有些不运行就难以发现的异常也是checked异常)。
可以通过继承来定义新的异常类型。
异常的抛出与处理
在异常问题中,事件的主体有两个:
- 代码:代码中可以编写有效获取并处理异常的程序。
代码主动进行异常抛出使用throw new ExceptionType();
在函数声明时也可以使用throws来声明此函数可能抛出的异常类别:
1 | |
- JVM:当出现代码中未处理的异常时,JVM会在打印运行时的堆栈跟踪信息之后终止程序的运行。如下段代码所示(例)
1 | |
需要注意的是,在堆栈的跟踪信息中,每一步都有机会获取(catch)和处理异常,下级未处理的异常会被传递给上级调用函数,当异常层层上报都没有被有效处理,JVM就要插手打印信息并终止程序。
JVM在不经过代码时也可能抛出异常(如堆栈溢出)。
正确的异常处理方法为:
1 | |
值得注意的是,从JDK SE 7开始,允许catch中异常类型的合并:
1 | |
同样是从JDK SE7开始,尝试了一种新的“try with resource”(尚未研究,略)
强制类型转换与泛型
强制类型转换Casting
主要关注引用类型的强制类型转换问题,一般包含两个子问题:
- widening casting:具体->抽象,向上转换
从 低层次 类型T转换为 高层次 类型U。一般有以下三种情况:
子类对象T 转换为 父类对象U
子接口T 转换为 父接口U
T使用了接口U
类似多态问题
- narrow casting :抽象->具体,向下转换
从 高层次 类型T转换为 低层次 类型U。一般有以下三种情况:
父类对象T 转换为 子类对象U
父接口T 转换为 子接口U
U使用了接口T
一般来说,向上转换比较安全,编译器可以自动认定转换的正确性,但向下转换不行。
因此产生了运算符**instanceof**,语法为
Obj instanceof Type
当强制转换出现问题时,会出现ClassCastException异常
泛型Generics
泛型产生的对应需求是,需要将同一类功能实现到不同类型的数据上,而不针对每个特定的类型都造出重复的车轮子。
- 泛型的前世
泛型时自Java SE 5才开始有的,在此之前,使用Object类进行相似功能,如:
1 | |
由于Object的所有类型的父类(超类),因此可以接受所有类型的向上强制类型转换,所以看上去是个很好的选择,比如:
1 | |
上述代码的初衷在于使用一个String类型创建一个Test实例test,然后获取其中存储的内部变量赋值给String对象ret。
但事实上,这是不安全的甚至编译不会通过,因为在最后一行代码中,涉及到了将test对象内部存储的Object对象test.A向下转换到类型String,因此需要显示强制类型转换:
1 | |
- Java SE 5 之后到泛型
泛型支持在类型定义中使用参数化的类型定义变量:
1 | |
上述代码中,声明了一个参数化类型T,并且在内部代码中视为一个已知类型使用,在实例化和后续使用时,如示例:
1 | |
上述代码中,声明Test类型的实例test时,指定了Test内部的参数化类型为String,因此在实例test内部将T类型视为String类型,所以对于方法test.Method()返回的也自然就是String类型的对象,不需要进行类型转换了。
按照代码书写惯例,参数化类型一般采用单个大写字母。
需要注意的是,代码中“可选1”和“可选2”是两种实例化方法,最初是使用“可选1”的风格。在Java SE 7之后为了简化,采用了“可选2”的风格,这种风格也常被称为“菱形语法”,赋值时自动匹配待赋值引用变量声明时所规定的泛型类型。
如果没有指定类型test = new Test(str),则视为使用经典类型(Java SE 5 之前),泛型被视为指定成Object类型
泛型不接受基本类型的制定,如double需要制定为其包装类型Double。
- 泛型与数组联合使用的风险
泛型对象和数组一起使用时存在不安全的风险,具体来讲,Java允许使用带泛型的数组声明,但是不允许在实例化(new)的时候生成泛型实例直接赋值给数组。可以接受的折衷办法是使用旧版方法(不使用菱形语法)然后经过强制类型转换赋值给对应数组,尽管此办法可行,但编译时仍会报出warning,因为这是不安全的。一般以下两种情况会遇到此风险。
-> 外部创建泛型类的数组
1 | |
-> 泛型类内部创建泛型类数组
1 | |
- 方法中使用泛型
1 | |
- 限定泛型范围
1 | |
将泛型A可以指定的类型范围强制限定为某个已知的类型范围内,保证内部某些方法的可用性。
反射Reflect
代码引入:
1 | |
乍一看很蒙,这就是反射的第一印象,这东西不理解的时候看起来很蒙,理解之后看起来就很容易懂了。
反射的理解层面
反射的具体使用
获取Class类对象(字节码信息)的几种方法
1 | |
注意:
- 若判断
cls1==...==cls4会返回true,因为他们都代表同一个类别Test的字节码。 - 方法3是最常用的,用于动态指定操作的类、对象、方法等。由于其他三种方法中都已经包含指定特定的类、对象、方法进行操作,一般不会应用到反射的最大应用场景——动态指定类和对象。
获取类的构造器以及对象的创建
1 | |
获取类的属性和赋值
1 | |
获取类的方法和调用
1 | |
反射值得思考的问题
- 简而言之,反射的用法很多,功能很强大,除上述用法之外,还可以获得其父类、接口、注解等一系列信息,具体实现方法可以参考API文档。
- 反射的规律性,反射的功能很多,但是从规律上而言,大致可以这么看:批量获取所有目标可以调用getXxxs()或者getDeclaredXxxs()方法,获取单个目标可以调用不带s版本的对应方法。获取public目标可以调用getXxxs() 或者getXxx(…),获取非public目标可以调用对应方法的Declared版本。
- 反射是否破坏了面向对象的封装?回答:事实上确实破坏了,但是反射有它自己的实现环境,迎合了一部分需求。应该尽量保持面向对象的封装型,但在一定的需求情况下考虑变通。打个比方,1、男生不能进女厕所,2、女生不能进男生宿舍。
注解Annotation
注解的理解层面
严格来说,注解对程序的逻辑实现没什么用。注解起到的作用是,在程序中充当提醒的角色,提醒程序猿、编译器等一系列让程序debug向正常运行方向的主体。
比如:
1 | |
这段代码的目的是重写某个主体内部的method1()方法。如果程序猿不写@Override,程序也能正常编译,如果逻辑没问题的话正常运行。但是一旦程序猿犯困,嘛method1方法名写错了,如果不写@Override的话,程序会继续创建一个新方法,默默无闻,傻不拉几;如果@Override存在,编译器会发现卧槽,你这方法我以前没见过,怎么重写?是不是你拼错了还是发生了啥?醒醒!
常用的三个注解
1 | |
注解的自定义
1 | |
元注解
1 | |
I/O
Java的IO的四大基类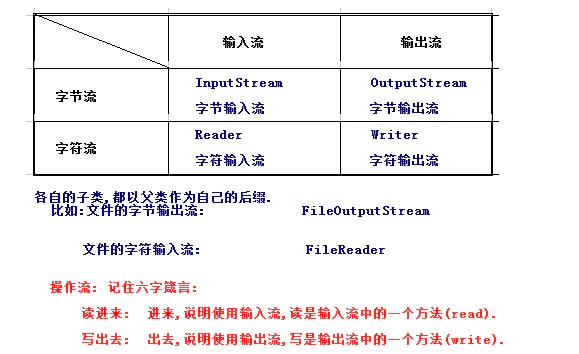
File类(java.io.File)
File类的理解:将系统中的文件、文件夹抽象为File类(联想到Linux系统中“万物皆文件”),如无特殊说明,本段后续统称文件和文件夹为文件。
File类的基本使用:
1 | |
那么这个路径到底对不对呢?
在程序执行过程中,如果路径出现问题,会报错。
一般来说面临两个问题:
- 路径拼错了
- 对应目录不存在
对于路径拼错这个问题,双十一重新买双手买个脑子能解决。
对于对应目录不存在这个问题,如果进行后续操作会遇到问题,比如打开一个不存在的文件,这是比较反智的。因此一般会进行如下操作:
1 | |
流
File类关注文件本身,可以操作文件的各种属性。但对于文件内部的具体内容,需要引入流的观念。
流的分类
输入流和输出流
“流”可以分为输入输出流,类比物理学的“参考系”说明方法而言,如果以Java程序为参考系,Java获取到的数据就是输入流,Java送出的数据就是输出流。
字节流和字符流
字节流:(Byte Stream)针对二进制类型数据
字符流:(Char Stream)针对字符类型数据
具体使用字节流还是字符流还是要看要操作什么类型的数据。都是统称,下面还包含很多东西。
节点流和处理流
节点流:直接和操作对象接触
处理流:处理已经存在的流(包括节点流和处理流)
字节流:InputStream接口、OutputStream接口
FileInputStream类、FileOutStream类
读取文本和写入文本
1 | |
字符流:Reader接口、Writer接口
Reader接口 实现类
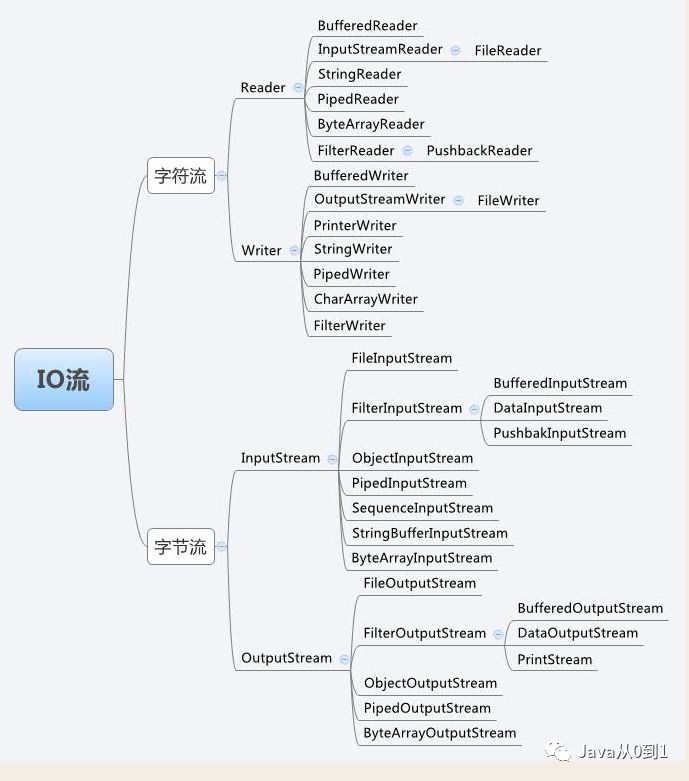
BufferedReader
FileReader
InputStreamReader
…
InputStreamReader类
InputStreamReader和FileInputStream很像,一个是按字节byte读取,一个是按照字符char读取
1 | |
FileReader类
1 | |
BufferReader类
1 | |
Writer接口 实现类
与Reader接口差不多,对应理解即可
IO流的关闭
JDK1.6之前需要手动关闭,之后Java可以自动关闭
1 | |
推荐博客:
1、juejin.im/post/6844903910348603405
2、赵彦军的博客(CSDN)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!